앞서 다룬 로짓모형 https://signature95.tistory.com/10?category=986931 에 이어서 작성하는 포스트입니다.
로짓분석
로짓 분석을 설명하기 앞서 선형확률모형에 대한 언급을 하도록한다. (로짓 분석을 왜 이용하는지에 대한 배경이 되기 때문이다.) 선형확률모형 (LPM) feature(설명변수)의 값이 주어졌을 때, label(
signature95.tistory.com
로짓 모형의 추정은 개별수준 (특정인이 흡연할 확률) & 그룹수준 (특정 그룹이 흡연할 확률) 등으로 구분지을 수 있다.
일반적인 OLS와 다르게 일반적인 모델의 추정 방식을 사용할 수 없다.
이 식을 한번 보자

이때, p=1 or 0인 경우, L은 다음과 같다.
ln 내에 들어가는 값이 0 일때는 -∞로 부여되고 값이 ∞일 때는 ∞로 된다.
우리는 L이 odds ratio에 자연로그를 취한 값이라는 것을 앞선 포스트에서 정리한 바 있다. 위와 같이 자연로그의 특성이 있기 때문에, 최우법(ML)을 이용하게 된다.
그렇다면 최우법은 어떤 것일까?
최우법 (Method of maximun Likelihood, ML)
OLS와 ML(최우법)의 차이를 언급하면서 시작하겠다.
OLS는 잔차에 대한 가정을 평균이 0이고 분산 (σ^2)이 일정하다는 동분산성을 가정한다. 이를 표현하면 다음과 같다.
하지만, 최우법(ML)은 잔차가 정규성을 가진다는 가정이 필요하지 않다. 대신 잔차의 분포가 로짓 분포를 따른다는 가정을 하고 있다.
정리하자면, 회귀계수의 추정 방식은 동일하지만, 잔차의 분산에 대한 추정이 다르다는 점이 OLS, ML의 차이다.
물론 대표본에서는 차이가 미비하다고 한다. (대표본은 보통 sample의 개수인 n이 30이상인 표본을 의미한다.)
그렇다면, 식에 대해 더 접근해보자.
앞의 IIDN을 가져온다면 식을 다시 쓸 수 있다.
이 식을 해석하면, 여기서 Y는 안정적인 모수(Population)이고 정규분포로서 IIDN (각각 독립적이고 동일하게 분포되어 있다)을 따른다. 그리고 Y는 잔차를 제외한 B + BX 와 σ^2 로 구성되어 있다고 할 수 있다.
그렇다면, Y는 정규분포를 따르기 때문에, 확률 밀도함수로 다시 정리할 수 있을 것이다.
참고로 분산과 평균이 정해진 X라는 명목변수의 확률밀도함수는 다음과 같다.
https://ko.wikipedia.org/wiki/확률_밀도_함수
확률 밀도 함수 - 위키백과, 우리 모두의 백과사전
ko.wikipedia.org
그렇다면, Y의 평균과 분산을 알기 때문에, Y의 확률밀도함수는 다음과 같이 정리할 수 있다.
이를 해석하면, i가 일어날 확률이 f(Y)로 표시된 것이다.
그렇다면, n개의 표본이 있는 Y전체의 결합확률분포는 다음과 같이 표현할 수 있다.
만약, Y를 알지만 B, σ등을 알지 못하는 경우 위 식을 우도함수(Likelihood Function, LF)라고 부른다.
최우법 (Method of maximun Likelihood, ML)은 이름에서 추정이 가능하듯, Y를 추정할 가능성을 극대화하는 방법이다.
그런 형태로 parameter(모수)를 추정하게 되는데 이는 양변에 log를 취하면 된다.
여기 식을 보면 마지막 항이 음수임을 알 수 있다.
여기서 최대를 구하려면, (Y-B1-B2X)^2를 최소화하는 값을 찾으면 되는 것이다.
최솟값을 찾는 것은 OLS 추정과 동일하게 편미분을 사용하여 B1, B2(파라미터)를 추정할 수 있다.
하지만, 우리가 주목해야 하는 부분은 분산의 추정이다.
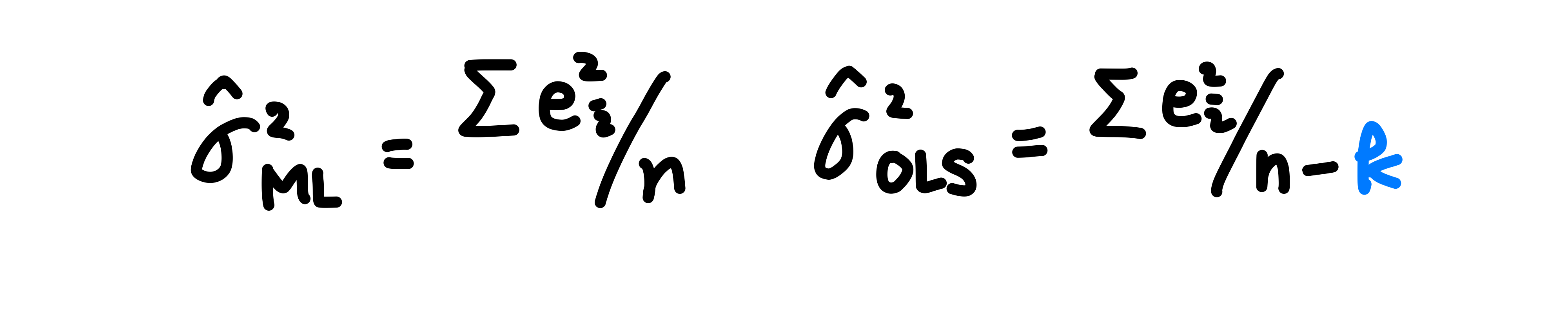
차이는 k에 있다. (k : 자유도, degree of freedom)
ML은 분산추정을 자유도로 바로잡지 않는 반면, OLS는 자유도로 추정량을 바로잡고 있는 것을 확인할 수 있다.
하지만, 대표본에서는 ML, OLS의 추정량은 거의 유사하다. (또한, 오차항이 정규분포라고 가정했기 때문이기도 하다)
또한, ML은 바람직한 대규모 추정량의 특성을 가지고 있다.
ML estimator의 특징은 다음과 같다.
1. 비대칭적으로 bias 되어 있지 않다.
2. 일치성이 있다
3. 점근적인 효율성이 있다. (대표본의 경우, ML의 분산이 가장 작음)
4. 점근적으로 정규분포를 이룬다.
OLS에서의 모형 적합성은 R-squared 값으로 해석한다. ML에서는 의사 R(pseudo R-squared)이다.

LF(L) : 분석하고 있는 모형 자체의 ML값
LF(L0) : 분석하고 있는 모형에서 절편을 제외한 ML값
절대치를 보면, L < L0 이므로 pseudo-R-squared 값은 0,1 사이로 된다.
그렇다면, OLS의 F 통계치와 같은 개념 (모든 feature의 파라미터가 0이다)은 우도비통계치(람다 : λ)를 사용한다.
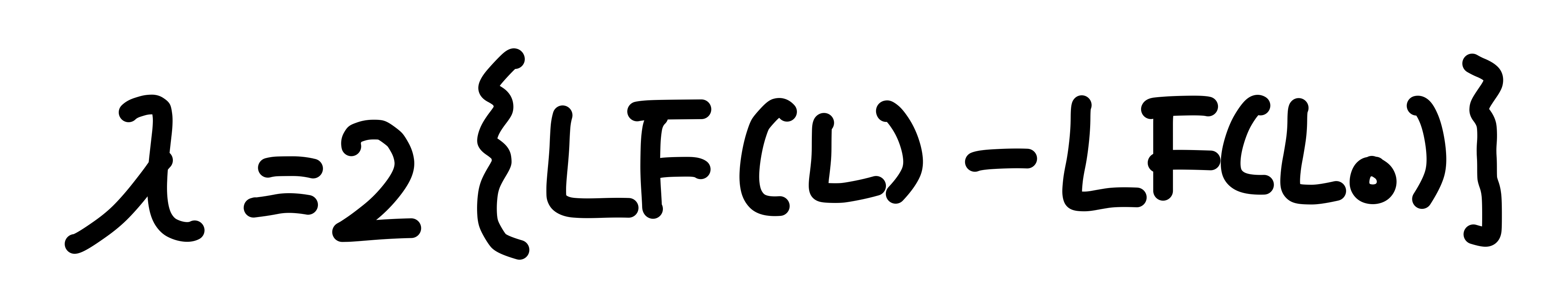
이제 ML에 대한 내용은 어느정도 정리가 되었으니, 다시 로짓분석으로 넘어가도록 한다.
로짓분석은 분석에 사용되는 자료의 형태에 의존한다. 이는 크게 2가지로 구분된다. (개별수준 자료와 그룹수준 자료 : 앞에서 언급하였음)
개별분석의 결과는 어떻게 해석할까?
먼저 추정방식이 최우법을 사용한다고 언급한바 있다.
파라미터(feature의 계수)에 대한 해석 (일반적인 OLS)
다른 조건이 일정할 때, 특정 feature가 1단위 변화한다면, 로짓의 평균값을 파라미터만큼 증가시키는 것이다.
예를 들어보자. 흡연을 결정짓는 변수 중 교육기간이라는 feature가 있다. 여기서 해당 feature의 계수는 -0.09라고 추정하였다. 이 모델을 해석하면, 교육기간이 1단위 증가할 때, 로짓의 평균값이 0.09만큼 감소한다고 해석할 수 있다. (로짓의 평균값 = odds ratio의 로그값)
위의 해석은 일반적인 OLS에서 적용할 수 잇다. 하지만, 로짓모형이나 프로빗에서는 한계효과를 이렇게 단순하게 구하기는 어렵다.
모형에서 흡연을 선택할 확률은 교육기간 1단위의 증가에 따른 변화뿐 아니라 변화가 발생한 이후의 확률수준에도 의존하기 때문이다.
따라서 이번에는 로짓과 프로빗에 적용되는 한계효과를 구해보자.
한계효과의 해석(로짓,프로빗) (개별 feature의 변화에 대한 한계효과가 아닌, 모든 feature의 평균이 1단위 증가할 때 한계효과를 의미함)
여기서는 다른 조건이 일정할 때, feature의 평균값이 1단위 증가할 경우의 한계효과를 계산한다.
위의 예를 다시가져온다면, 교육기간의 평균이 1단위 증가할 때, -0.021만큼 흡연할 확률이 감소하는 것으로 도출된다. (물론 위의 계수와 다른 것은 애초에 추정방식이 위는 OLS, 여기선 logit이기 때문이다)
참고로, 파생변수를 만들 수도 있다.
만약, 교육기간의 P값이 0.05를 넘는다면, 이는 통계적으로 유의하지 않다고 판단할 수 있다. 이때, 다른 변수(예를들면 소득)와 곱한다면 다음과 같이 해석할 수 있다.
교육과 소득을 곱한 계수의 값의 p값이 유의하고, 교육 계수와 소득 계수보다 곱한 값의 계수가 크다고 가정하자.
그렇다면, 교육수준과 소득수준이 높은 사람은 흡연을 할 확률이 더 높다고 판단할 수 있는 것이다.
이번엔 그룹차원의 자료를 생각해보자.
예시를 가져와서 60명의 관측치가 있는 20개의 그룹이 있다. 이 개별 그룹에서 흡연자 수를 각각 찾아서 n(i)로 나타내고 n(i)/60을 구해주면 각 그룹에서 흡연을 선택할 p(i)(i 번째 그룹내 흡연자 비중)을 실증적으로 구할 수 있는 것이다. (여기서 i는 i 번째 그룹을 의미한다. 따라서 n(i)는 i번째 그룹 내의 흡연자 숫자이다.) 그래서 도출한 p(i)으로 로짓모형을 OLS를 통해 도출할 수 있다.
하지만, 주의해야할 점이 몇개 존재한다.
1. 자료에서 그룹 i를 몇개 정해야하는지?
p(i)의 개수를 결정짓는 것인데 너무 많으면, 그룹 내의 관측치가 적어진다. 반면 i가 너무 적으면 적은수의 p(i)를 형성하여 로짓 모형 추정이 어려워진다.
2. 적합한 i를 선택했는데도 그룹 별 오차항이 이분산성을 가질 우려가 있다.
이를 검정하는 방식으로는 white Test, BP-test가 있다. 만약 이분산성이 있는 경우에는 White-Robust-Standard_error를 사용한다.
프로빗
이번엔 프로빗을 살펴보자.
로짓과 프로빗의 차이는 무엇일까?
가정의 차이가 있다.
로짓모형의 오차항은 로짓분포를 따른다. 하지만, 프로빗은 오차항이 정규분포를 따른다는 가정으로 접근한다.

보라색 : 흡연자로 분류(Y=1)되는 X의 비율을 의미한다. (확률변수X가 주어졌을 때, 사건이 발생할 확률)
파란색 : 프로빗 모형에서 I*가 I보다 작을 확률로 보라색과 동일한 의미로 보면된다. (작은 경우 흡연자로 분류된다)
초록색 : 파란색에 있던 I* 는 Z(표준정규분포를 따르는 확률변수)로, I는 BX로 보면된다.
따라서, F(BX)는 위의 식을 축약한 함수로 보면된다.
여기서 F는 표준정규누적분포함수를 나타낸다.
F(BX)를 식으로 쓰면 다음과 같다.

BX = I 와 같은 의미인데, 이를 활용하여 위의 식을 해석해보자.
어느 한사람이 흡연을 선택할 확률은 구간 [-∞, I ]에서 표준정규누적분포함수의 면적으로 주어진다. 이를 F(I)로 표현하고 프로빗함수라고 부른다.
프로빗 모형에서 계수를 추정하는 방법은 일반적으로 ML(최우법)을 사용하게 된다.
그렇다면 해석은 어떻게 하는가?
위의 교육변수를 가져오면, 프로빗 모형에서는 -0.056으로 계수가 도출된다. 이에 대한 해석은 로짓분석과 다르지 앟다. 즉, 교육의 평균이 1단위 증가할 때, 흡연을 할 확률이 -0.056감소한다고 보면 되는 것이다.
여기서 더 나아가 프로빗의 계수와 로짓의 계수를 직접 비교할수도 있다.
하지만, 오차항에 대한 가정이 로짓과 프로빗이 상이하기 때문에, 우리는 전환율을 곱해줘야 한다.
표준로짓분포와 표준정규분포의 평균은 0이지만, 분산이 다르다.
표준로짓분포의 분산은 {(π)^2 }/ 3이지만, 표준정규분포의 분산은 (1)^2 이다.
그리고 표준로짓분포는 로짓에서, 표준정규분포는 프로빗에서 사용한다.
따라서, 프로빗 모형의 계수에 전환율 (표준로짓분포의 표준편차, 약 1.81)를 곱해줘서 근사시켜 직접 비교를 할 수 있는 것이다.
| 로짓모형 | 오차항이 로짓분포를 따른다. | 표준화된 로짓분포의 분산은 {(π)^2 }/ 3이다. |
| 프로빗모형 | 오차항이 정규분포를 따른다. | 표준화된 정규분포의 분산은 (1)^2 이다. |
분산이 크다면, 분포의 양끝단이 두툼하게 된다. (고르게 퍼져있기 때문)
이제 결론이다.
로짓과 프로빗의 추정 결과는 유사하다. 해석도 동일하게 적용할 수 있다. 하지만 분산의 차이가 있기 때문에 분산이 더 큰 로짓분포(약 1.81의 제곱으로 프로빗에서 오차항의 분산이 1인 것보다 큰 값을 가진다)의 양 끝이 더 두툼하게 된다. 따라서, 조건부 확률 P가 0,1로 수렴하는 속도가 다소 느리다는 점이 있다.
실증분석을 수행할 때는 두 모형간 큰 차이가 없기에 어떤 모형을 선택하더라도 큰 차이는 없다. (다만 가정에 대한 차이는 주의해야한다)하지만, 수학적 편의성으로 프로빗보다는 로짓을 더 많이 이용한다고 알려져 있다.
'공부 > 통계학' 카테고리의 다른 글
| 등분산 검정 (파이썬) (0) | 2022.01.11 |
|---|---|
| 정규성 검정 (Python) (0) | 2022.01.11 |
| Chi-square-test (카이제곱검정) (0) | 2021.11.18 |
| T-test (T 검정) (0) | 2021.11.17 |
| 로짓분석 (0) | 2021.11.16 |




댓글